Definition der Semantik von Verknüpfungsketten
und Formulierung eines darauf beruhenden Regelkatalogs
INHALT: Einleitung
| Inferenzregel | Regelanpassung
Die Eingabe von Beziehungen zwischen potential Taxa
[1] und die sich daraus ergebenden
Konsequenzen für die Übertragbarkeit von Sachdaten können als Bestandteile
eines "Expertensystems" aufgefasst werden:
-
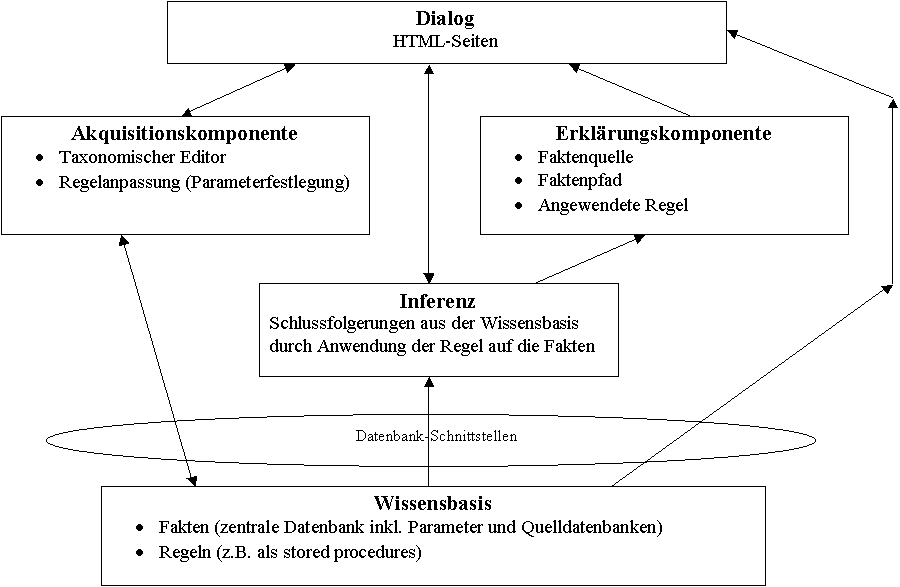
Das Wissensbasismodul besteht aus den
potential Taxa mit ihren Beziehungen untereinander, aus den mit diesen
potential Taxa verknüpften Sachdaten sowie aus Regeln bezüglich den
Beziehungen und Sachdaten.
-
Das Inferenzmodul liefert neue
Erkenntnisse, indem die Regeln auf bestimmte Fakten (potential Taxa,
Beziehungen und Sachdaten) angewendet werden.
-
In der Erklärungskomponente wird die
Vorgehensweise des Systems transparent gemacht und dem Benutzer sowohl der
Lösungsweg als auch eine Begründung für die ermittelten Erkenntnisse
gegeben.
-
Schließlich
werden in der Akquisitionskomponente die Mechanismen zusammengefasst, die
zur Pflege und Aktualisierung der Wissensbasis eingesetzt werden. Dabei
handelt es sich um die Module Taxonomischer Editor (Erfassung der
potential Taxa und Eingabe ihrer Beziehungen) und Regelanpassung (Schnittstelle
zur Parametrisierung einzelner Inferenzregeln und ausgabebezogenen
Funktionen).
Die folgende Abbildung skizziert die Architektur
eines solchen Expertensystems mit World Wide Web Schnittstelle.
Inhaltlich gehören zu diesen Inferenzregeln insbesondere:
-
Regeln, welche die
Operationen auf Beziehungen beschreiben
-
Regeln, die zur
Berechnung der abgeleiteten Beziehung zwischen zwei potential Taxa dienen
-
Die Regel, welche
ankommende Informationen bewertet
2.1. Die Regeln, welche die Operationen auf Beziehungen beschreiben[2]
-
Enger Konsens:
Schnittmenge von zwei zusammengesetzten Beziehungen.
-
Breiter Konsens:
Vereinigungsmenge von zwei zusammengesetzten Beziehungen.
-
Umkehrung:
Berechnung der zusammengesetzten Beziehung B2 zwischen den
potential Taxa PT2 und PT1, wenn B1 die
zusammengesetzte Beziehung zwischen PT1 und PT2 ist.
-
Negation:
Berechnung der zusammengesetzten Beziehung B2 bei Verneinung der
Beziehung B1.
-
Verkettung:
Berechnung der zusammengesetzten Beziehung B3 zwischen den
potential Taxa PT1 und PT3, wenn einerseits B1
die zusammengesetzte Beziehung zwischen PT1 und PT2 und
andererseits B2 diejenige zwischen PT2 und PT3 ist.
2.2. Regeln (und Bedingungen),
die zur Berechnung der abgeleiteten Beziehung zwischen
einer potential Taxon Quelle PTq und einem potential Taxon Ziel PTz
dienen
-
Die Wege zwischen PTq
und PTz werden als Abfolge von Kanten ermittelt. Innerhalb eines
Weges darf kein potential Taxon zweimal vorkommen (Vermeidung von Zyklen).
Innerhalb eines Weges dürfen zwei aufeinanderfolgende Kanten mit
Klassifikationsbeziehungen nur vorkommen, wenn diese dieselbe hierarchische
Richtung (im Sinne der Rangfolge) ausweisen.
-
Wird in einem Weg eine Kante mit der Beziehung disjunkt ({!}) erreicht,
so wird der Weg an dieser Stelle abgebrochen
-
Kommt für einen Weg eine Kante in Frage, welche dieselben beiden
potential Taxa wie andere Kanten (mit entsprechenden von verschiedenen
Beziehungsautoren festgelegten Beziehungen) vorweist, so wird anhand der
Gewichtungen
eine für dieses potential Taxon Paar gültige Ergebnisbeziehung berechnet und
diese bei der Bewertung des Weges (d. h. der Zuordnung einer Beziehung) berücksichtigt.
-
Jeder Weg wird bewertet, indem ihm eine Beziehung - anhand der Verkettung
der jeweiligen (Kanten-)beziehungen und deren Gewichtungen - zugeordnet.wird.
Jeder Weg wird ebenfalls gewichtet.
-
Die abgeleitete Beziehung zwischen PTq und PTz wird
anhand der Bewertungen aller ermittelten Wege und deren Gewichtungen berechnet.
2.3. Die Regel, welche ankommende Informationen qualifiziert
-
Die ankommenden Informationen werden anhand der ursprünglichen
Informationskategorien
und der berechneten Beziehung zwischen PTq und PTz
qualifiziert.
Die Systemverwalter sollen in der Lage versetzt werden, nutzertypspezifische
Rahmen vorzudefinieren, innerhalb derer bei der Formulierung von Abfragen am
System weitere Modifikationen und Einschränkungen vorgenommen werden können.
Dieser Rahmen besteht aus einigen festzuhaltenden Werten, die folgende Prozesse
grundsätzlich regulieren bzw. einschränken:
-
Die
Einbeziehung von Kanten wird zusätzlich durch eine Gewichtung der
Beziehungsautoren und durch ein minimales Gewicht, unterhalb dessen die
entsprechenden Kanten nicht berücksichtigt werden, reguliert.
Diese
Gewichtung sowie die Ausschlussschwelle werden als Parameter an die Regeln 6 und
8 übergeben. Die Ausschlussschwelle wird ebenfalls an die Regel 10 übergeben.
-
Die
Ermittlung der Wege wird durch die Festlegung der maximalen Länge der zu
berücksichtigenden Wege, der maximalen Anzahl der einzubeziehenden
Klassifikationskanten (jeweils höhere bzw. niedrigere potential Taxa – für
alle Quellen insgesamt oder pro Quelle) sowie der Gewichtung für einzelne
Beziehungen (eine Kongruenzbeziehung könnte z. B. bei der Bemessung der Länge
ignoriert werden) eingeschränkt.
Diese
vier Werte und diese neue Gewichtung werden als Parameter an die Regel 6 übergeben.
-
Die
Gewichtung eines Weges erfolgt durch die Anwendung einer auswählbahren
mathematischen Operation auf die Gewichtungen der Kanten.
Diese
Operation wird als Parameter an die Regeln 8 und 9 übergeben.
-
Das
Verfahren im Falle „simultaner“ Beziehungen wird durch die Angabe des
Beziehungsoperators („enger“ oder „breiter“ Konsens), der
maximalen vorkommenden Gewichtung und des zulässigen Intervalls
festgelegt.
Diese
Werte werden als Parameter an die Regeln 8 und 10 übergeben.
-
Die
Ausgabe für Benutzer wird nicht vom Inferenzmodul gesteuert, sondern von
einem bisher noch nicht spezifizierten „Ausgabemodul“ mit eigenen
Prozeduren und Regeln. Dennoch bietet sich an, in dem hier beschriebenen
Rahmen, Initialisierungsparameter für differenzierte Ausgaben festzulegen:
a)
niedrigste Informationskategorie, die zur Anzeige
zugelassen wird,
b) Anzeige und Kommentierung der Informationen aus einer bestimmten
Sachdatenquelle in Abhängigkeit des Nutzertyps und der Qualität dieser
Sachdatenquellen (Nutzertyp, Quelle, niedrigste Informationskategorie und
Kommentar werden als Parameter übergeben),
c) Anzeige und Kommentierung der Informationen in Abhängigkeit des
Nutzertyps und des Risikoinhalts der Sachdaten (Nutzertyp, Risikoinhalt,
niedrigste Informationskategorie und Kommentar werden als Parameter übergeben).
Es handelt sich also insgesamt um die Steuerung von Regeln und Prozeduren
durch die Festlegung von Parametern. Diese Parameter werden in einer
Konfigurationsdatei festgehalten. Zur Pflege und Strukturierung einer solchen
Konfiguration eignen sich XML-Dateien.
|
|
Beispiel für eine XML-Konfigurationsdatei:
<?xml version="1.0" encoding="UTF8" ?>
<Parameters Who="Mgeo" When="20-11-01" xmlns:xsi="http://www.w3.org/2001/XMLSchema
instance" xsi:noNamespaceSchemaLocation="Parameters1.xsd">
<AuthorPriority NumOperation="Minimum">
<AuthorID Weight="100">10</AuthorID>
<AuthorID Weight="80">24</AuthorID>
</AuthorPriority>
<Simultaneity StandardDistance="20" StandardOperator="Schnittmenge"
StandardExclude="10">
<IntersectionByWeight FromWeight="10" ToWeight="75"
Distance="30">false</IntersectionByWeight>
</Simultaneity>
<PathLength Length="8" MaxLowerTaxa="0">
<RelationshipWeight RelationshipNumber="1">0</RelationshipWeight>
</PathLength>
<MinInfoCategory>maybeForSome</MinInfoCategory>
<SourceEvaluation>
<Source Id="12">
<allUsers>
<Commentary>Keine wissenschaftliche Quelle </Commentary>
<MinInfoCategory Doubt="false">forSome</MinInfoCategory>
</allUsers>
</Source>
</SourceEvaluation>
<InfoEvaluation>
< ConfidentialityCat Confidentiality ="sehr sensible">
<allUsers>
<MinInfoCategory>forSome</MinInfoCategory>
</allUsers>
<User>
<UserType>Laie</UserType>
<MinInfoCategory>doNotUse</MinInfoCategory>
</User>
</ConfidentialityCat>
</InfoEvaluation>
</Parameters>
|


{kind=link}