 |
Resource Identification for a
Biological Collection Information Service in Europe Results of the Concerted Action Project |
|
Resource Identification for a
Biological Collection Information Service in Europe Results of the Concerted Action Project |
[Contents] [BioCISE Home | The Survey | Collection catalogue | Software | Standards and Models]
Walter G. Berendsohn, Mark J. Costello, Chris Emblow, Anton Güntsch, Andrea Hahn, Jürgen Koenemann, Christoph Thomas, Neil Thomson and Richard White
Pp. 59-70 in: Berendsohn, W. G. (ed.), Resource Identification
for a Biological Collection Information Service in Europe (BioCISE). - Botanic
Garden and Botanical Museum Berlin-Dahlem, Dept. of Biodiversity Informatics.
The accessibility and thus use of biological collections would be significantly improved by a common "portal" through which information on the holdings of research institutes, museums, survey organizations etc. can be accessed. This portal may take the form of an Internet site where the reader can search for information based on biological names, taxonomic groups, habitat names (e.g. marshes), ecological relationships between species (e.g. parasitism), and geographic sources of specimens and observations of species. Unfortunately, such a search facility is far more complex than immediately apparent. One of the main obstacles is that collections use terminology going back 300 years and it is not feasible for most facilities to update their data comprehensively with changes in taxonomic nomenclature and geographic or political boundaries. However, we posit that this problem, as well as the difficulties created by the fragmentation of the collection community itself (see box on p. 3) can be overcome by a pragmatic and concerted effort of the interested parties.
Channelling collection information into a common access system makes sense because
In the process of assessing user requirements and available resources on the provider's side it became clear that such a service had to be very flexible; scalable on the collection owner's (provider's) side, simple in its internal mechanisms, broad in its cover of collections from different sub-disciplines, and providing a user interface adaptable to users' needs. Realising that an extensive Europe-wide specimen ("unit") -based access system is not yet within reach, but that user demand exists for concerted access to collection information right away, it was decided to focus on the creation of a collection-level information system as the kernel of "The BioCISE". However, from the beginning a unit-level approach should be integrated (see Chapter IX). Recent initiatives, particularly the formation of - and EU support for - the European Natural History Specimen Information Network (ENHSIN 2000) are a promising proof of intent on both the information providers' and the funding agencies' side.
As has been shown in Chapter X, the physical as well as the information content
of biological collections can be described using meta-information, i.e.
information linked to sets of units. The interesting fact about such metadata
items is that - with few exceptions - they are applicable to both, unit-level
and collection level.

Figure 13: Physical hierarchy of reference points for collection meta-information
This presents a first important chance to achieve scalability of the system. Generally, the information referring to a high level in the physical hierarchy (fig. 13), an entire Natural History Museum for example, will be much less specific than that referring to a single unit. However, exceptions can be found e.g. in specialised collections, which consist of only one species, as well as in reference collections for a specific site.
The meta-information can be at any level of detail, from the very general (plants, Europe, 19th century) down to the very specific (the species, detailed gathering site, date). Between these extremes a fluent transition exists because most of the important data items describing collections and units are belonging to a (more or less) hierarchical classification system (e.g. geographical: country - department). This is the second important factor, which can contribute to achieving a scalable system. A system using meta-information organized into such a schema will allow processing of very detailed collection descriptions but still be able to provide information on collections that cannot or do not want to supply this kind of detail. It will enable researchers to locate needed information or materials and obtain them by conventional means, if necessary.
In addition, meta-information may serve as a valuable enrichment of unit data especially when statements about data quality and procedures are provided. However, at present, the major advantage of metadata lies in the fact that they can provide information about - and facilitate access to - units even where unit-level data are not available.
Identified priorities. The two most important data areas for meta-information about collections are names of organism groups and named areas (the latter using geographical, biogeographical, geological, palaeontological or ecological terminology). Unfortunately, these areas are not stable: terms may have different meanings depending on who applied them and when (e.g. "Germany", "Liliaceae"). Moreover, geoecological and taxonomic class names represent scientific concepts, thus parallel, partly overlapping hierarchies may exist (e.g. generic and family delimitation in systematics).
Consequently, no single standard hierarchy exists for any of these information domains. The development and application of integrated metadata 'thesauri' and classifications for these data areas is a prerequisite for the functioning of an extendible collection information service. To be clear: these will be pragmatic tools to facilitate access; they will not attempt to redefine terms or derive new classifications. They will allow searches by keyword and by following hierarchical links despite the underlying anarchy. Users must be able to select and/or specify fuzzy concepts such as habitat boundaries ("Rainforest") or undefined geographic terms ("Central Europe") that don't map easily to the political boundaries available in today's gazetteers and geographical information systems. Taxonomic concepts and names representing organism groups present similar problems of parallel and partially overlapping hierarchies. To include them in data access interfaces, information structures and methods which are able to accommodate and process such complex inter-relations between individual metadata elements must be defined.
The thesaurus forms a common source for both indexing of collections and the design of the portal's user interface (e.g. implementation of a convenient taxonomic browser instead of free text fields). The thesaurus to be constructed has to be powerful enough to treat various semantic relations such as synonyms and hierarchies. It has to put a special focus on taxonomic and geographic terminology to fulfil the special requirements of the biological community. National and thematic networks can derive keywords to describe their collections from this thesaurus to provide a homogeneous data source utilized by the central catalogue. In addition to data provided by the networks, rule based technologies can be used to represent complex weighted relations among thesaurus' elements and to further enrich the set of keywords by deriving useful categories from collection descriptions. Rule based indexing will reduce the costs for the time consuming process of human indexing.
Geo-ecological thesaurus. With respect to geo-ecological classifications of collections, two types of questions have to be addressed: The comparatively simple question of where a collection (institute) is located (e.g. "Is there a reference collection of microbial strains in town X?") and the much more complicated question where specimens collected at a defined site can be found (e.g. "Who has holdings of specimens from the northern Mediterranean coast?" or "Where can I find organisms collected from Late Triassic St. Cassian Formation?"). The data for the former question can be captured from rather standardised address information and related to existing data collections on present administrative boundaries. The compilation of metadata for the second question is difficult for various reasons. In contrast to taxonomic data, no agreed systems of nomenclature for geographic, ecological, or palaeontological "areas" exist. The catalogue has to deal with very variable applications of terms (e.g. "St. Cassian", "Sankt Cassian", "Cassinian" in the above example), consider provisions for changes in the delimitation of areas in time (e.g. in the case of "Germany" and "Yugoslavia"), consider the problems of more or less linear references ("Mediterranean coast", "River Guadalquivir"), vague delimitation ("northern Spain") and the problems of scientific concepts represented by ecological and palaeontological terms. The identification of existing data collections (e.g. available gazetteers) and the contacting of geographical and ecological institutes will be prominent approaches. The decision on practical cut-off points for the hierarchical representation of the data (as opposed to a synonymised keyword list) is fundamental. Mapping the European languages into such a thesaurus (initially to be implemented largely in English) is a problem, which is tackled extensively in various projects; collaboration has to be sought here as well.
Taxonomic thesaurus. Rules of nomenclature ("Codes", e.g. ICZN 1999, Greuter et al. 2000) exist for the area of taxonomic data (scientific names of organisms). However, synonyms, conceptual differences between applications of the same class name, as well as the problem of congruence of concepts with differing names also persist in taxonomy. This is the consequence of the naming system being a pragmatic approach to a rather complicated scientific problem: the classification of life on earth according to its natural evolution. Large data collections have already been identified which can be used to compile a catalogue of names down to genus level. This can be used as a backbone classification to which other terms can be associated. "Pseudotaxa", i.e. higher-level class names for organisms that do not directly correspond to a taxonomic group (e.g. "Medicinal plants", "Pests", "Birds of prey", "Trees", "Microbes") must also be treated.
Other data areas. Data areas that do not belong to one of the aforementioned categories must also be tackled. This covers, e.g., temporal aspects (date of collection event, dwelling time of the organisms in palaeontological contexts, etc.), representation of collection purposes (research material, archive of vouchers, exhibition, etc.) and preservation methods (often important for potential use of materials in analysis), among others. The compilation of such thesauri can be based on an analysis of the data provided by the BioCISE survey database and by looking at other similar data collections, to find out about terms applied by users in their queries, and terms used by institutes to describe their collections.
Modelling and implementing catalogues and their utilization in user interfaces are general tasks of informatics research and application development. A partnership with an information technology provider should be sought to avoid duplication of efforts.
A proposed representation of entire collections. Since biological collections
are generally organized hierarchically, it is straightforward to describe them
as trees, the nodes representing sub collections (sets of units), and the
connecting lines representing "is part of" relationships (fig. 14).
Each node is linked to sets of attributes (e.g. taxonomic identification,
ownership, locality) providing the sub-collections' properties (fig. 15). These
attributes are referenced in the metadata thesaurus and thus can be referred to
other, more general or more specific terms. Properties can be further quantified
by labelled links to express the fuzziness typical for collection descriptions
(e.g. "mainly" Coleoptera, "some" Lepidoptera). Available
metadata are often incomplete (for example if derived from questionnaires).
Adding "dummy" nodes labelled "other" can indicate this
(fig. 14).

Figure 14: Hierarchical structure of a selection of collections at the
Botanic
Garden and Botanical Museum Berlin-Dahlem (BGBM)
Güntsch et al. (2000) demonstrated the use of this representation to formulate rules to derive complex concepts describing classes of collections (e.g. "Natural History Museum", "Botanical Garden"). Future work will have to analyse the inheritance of properties within a tree representing both exact and fuzzy data to achieve a solid theoretical ground for the implementation of indexing modules, data capture tools, and user interfaces.
Information model. Documentation of heterogeneous information resources is a
current topic e.g. in library science, museology, and environmental and medical
informatics. The definition of meta-information attributes associated with
collections of biological material must be based on an evaluation of existing
and emerging metadata standards and work effected by current international
working groups involved in the standardisation of access to museum resources.
General metadata standards such as the Dublin Core definitions (Anon. 1998) must
be incorporated, too.

Figure 15: Sets of attributes providing (sub-) collection properties
The representation of hierarchical structures, use of controlled vocabularies, incomplete or fuzzy data, and administrative metadata are problems extending far beyond the scope of biological collections. Similar problems are encountered in the domain of environmental information systems (e.g. in the context of the European Topic Centre on Catalogue of Data Sources, EEA 1999) or have indeed been identified as an unresolved problem for all collections (including museums, documents, archives, subject gateways, etc.) by the collection description working group of UKOLN (UK Office for Library and Information Networking; see Heaney 2000). An important component of the design process for the European Collection Information Service will be the provision of a theoretical model which helps to find a practical solution to the problems addressed. The results influence the design of the metadatabase system directly, but also indirectly, by way of the content structure definition of the metadata catalogues.
User interface. There are some standard techniques to allow navigation in hierarchies. For example, in Yahoo!-style sites and most online shopping or product selection environment hierarchies, there are lists of links, and following a link will result in a new page being displayed, possibly with further lists of links until the terminal nodes of the hierarchy are reached. These types of interfaces work well with small hierarchies containing well-known entries but are inappropriate for the task at hand. Direct manipulation interfaces with very fast updates of displays in reaction to user input are needed, with displays that allow users to see and select content rather than having to specify their needs formally. These interfaces have to be tailored to the particular information at hand. Furthermore, interfaces will need to be personalised based on user characteristics and current task. For example, graphic browsing of a hierarchy with Latin names of species may be appropriate for experts who are familiar with taxonomic trees and the specialist terms. Conversely, novices may require a different structure and different terminology likely to be supported by visual means such as images and symbols.
Novel interaction techniques have to be developed, because users must be able to browse and search in multiple, linked hierarchies without loosing orientation, the system and its interfaces must represent missing, fuzzy, or incorrect (outdated) information, and users must be able to select and/or specify often fuzzy geoecological concepts.
Novel technical solutions will need to be developed to design and implement user interfaces that address these issues and at the same time support a large set of users with a diverse set of hardware (network bandwidth and processing speed) and software (browsers, Java, etc.) constraints.
Knowledge processing. In addition to evaluating distributed web sources, quite often new information can be extracted from the existing. This may concern the seemingly obvious one not thought to be necessary to put into (key)words: When searching for micro-organisms, looking into microbial collections seems the natural approach. But what is labelled as a "microbial collection"? Does a search for the keyword also answer with a cheese producer's Lactobacter strains, or an algal reference culture collection? Are we talking prokaryotes, unicellular, or just "small"? The task of a knowledge-processing module is to apply man-made rules for such definitions to existing data and thereby, for example, generate new keywords. Through the possibilities of assigning different weightings, probabilities may be calculated: Asking for micro-organisms should deliver all bacterial collections, but also offer others lower down on the list.
One problem will be that, even with good thesauri available, most of the information used in the service will not adhere to a single structure. For example, collections may represent the data related to the gathering of a unit as a single field of text, or they may provide this in a highly structured, atomised form. Detailed knowledge about the hierarchical decomposition of such information will be very useful in the process of extracting information from text sources, especially if combined with the thesaurus.
Synergetic effects. In the national meetings of collection holders organised or co-organised by BioCISE it became clear that the cross-subdiscipline approach was greeted with enthusiasm, but that communication even within sub-disciplines was generally wanting. Participants presented a multitude of isolated information systems developed or in preparation in their institutes (see Chapter VIII). The potential for synergetic effects was obvious. BioCISE was perceived as a possibility to focus resources and to overcome existing institutional rivalries or other political impediments, which may bear on the development of collaboration on the national level. In this context it is also important that almost all information providers would also be users of the service.
IPR and other legal concerns. Still existing impediments to the networking of unit-level data resources are the unresolved questions of IPR in databases and database networks (see Chapter II). Another important area of concern is the unresolved question of obligations imposed by the Convention on Biological Diversity (particularly in the case of living collections, which undoubtedly represent "genetic resources"). The use of metadata was greeted by some of the institutes with more advanced data holdings as a possibility to await a solution of these problems before going public with their data holdings, but at the same time being able to advertise their collection's scientific information content.
Promotion of collections. Collection holders also consider it essential to improve public understanding of the importance of natural science collections, and of the relationship between collection conservation efforts with the ability to manage, preserve, and interpret our natural heritage as well as the world we live in. One of the most important future tasks will be to show that the varieties of collections are actually daily used, and that they are of public interest. Hence the credit of the users will serve as motive to establish and to maintain a Collection Information System.
Data capture. As mentioned before, national meetings and spin-off activities led to the realization that the European service must rely on national networks or nodes to actually collect the information. For projects implementing such nodes national funding may be found - as has already happened in the case of Belgium, Austria, and Germany, and as it will hopefully be achieved in other European countries. The political argument in favour of such funding lies in the obligations incurred by government in the context of international conventions, the contribution to an over-all European research infrastructure, and synergetic effects to be achieved on all levels. However, governments and funding bodies do seem to believe that unit-level data capture is within the scope of individual institute's activities, so that successful attempts to find extra financing for such endeavours will probably remain the exception. For collection-level information, the BioCISE survey database can serve as an initial dataset to build upon.
National nodes. Regarding the access to technical innovation, Europe has grown
closer over the past years. In the implementation, and above all, population, of
biological collection information systems, however, it may still take a long
time to reach a common level. This does not demean the value of the collections
themselves but their chances to be recognised, preserved, and properly valued.
The aim of the National Node set-up is to provide equal chances for all of
Europe's biological collections to be represented in a common information
system. The metadata access system will help to override the inherent inequality
resulting from still widely differing access to information systems, databasing
expertise and staff supply. In some countries (e.g. Belgium), national
information systems are already well developed, needing little initial input to
adapt to contribute to a European system. In other cases providing the basic
means (software and training) for the initial set-up as a National Node will be
needed.
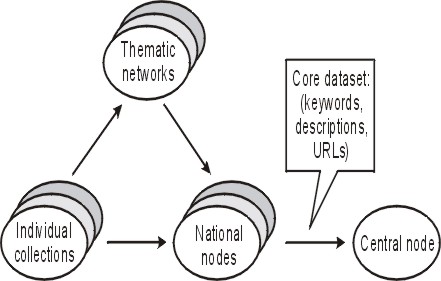
Figure 16: Information flow from individual collections to Central Node
The National Nodes are to co-ordinate networking at the national level, but to provide a common access point and a conceptional framework for the European system, a central system ("Central Node") is needed (which, however, has to be kept at a minimum to ensure sustainability). To make the information gathered by the National Nodes useful for the European system, standard protocols for metadata content and usage must be applied. This is most efficiently possible by providing the National Nodes with software which communicates with the central system's thesauri etc. and which can be accessed by the central system for information retrieval. The software has to be designed in an easy-to-extend fashion, using widely available software as its base, so that National Nodes can easily extend their activities.
The National Nodes should be hosted by organisations committed to research or
information provision on a national level, e.g. institutes being part of
national academies, or the academies themselves, organizations representing the
national clearing house mechanism, or other agencies with an obligation of
fostering the collection and maintenance of biological data. It is not
mandatory, but of advantage, if they are information providers and/or users
themselves, thus being beneficiaries of the improved information access the
European Service will provide. They will take on the responsibility of hosting
the national meta-database and setting up a website.

Figure 17: Feedback of information from Central Node towards National Nodes
Communication with the Central Node includes keeping up an interface to supply the necessary core data to perform searches over all connected databases (fig. 16), and to feed back enhanced quality data to the national system (fig. 17). The enhanced data result from the Central Node's application of knowledge processing and advanced indexing tools and the addition of information from different sources. Links to already operating thematic networks will be established, as demonstrated by the BioCISE project.
Automatic extraction of keywords. The efficiency of information access will to a large extent depend on the efficiency of linking metadata items in the thesauri to the collections or sub-collections. The central node will receive information from the national nodes in the form of core attributes and free text descriptions. One of the core attributes is the URL of the collection's website (if any). This can be used to implement web-robot techniques to analyse the websites and automatically extract keywords. For this, an advanced multilingual free text indexing tool has to be developed. Rule based techniques will then be used to work on both, the information retrieved from national nodes and that from Websites, to generate value-added indices. These can be used directly in the central user interface, but should also be communicated back as added value to the national nodes.
User access. Users will be able to choose between access via the European
Service, National nodes, thematic networks as well as access to individual
collections (fig. 18). Where available, the Service and the national nodes will
offer these choices to the user.

Figure 18: Access to collection information
Sustainability. Prospects for long term funding for the operation of a Biological Collection Information Service on the international scale are rather bleak. On the other hand, among participants in the various workshops and other providers and users interviewed, consensus prevailed that the service itself should be free of charge for the user. Such a facility certainly represents an infrastructure providing access to specimen data, which are the results of more than two centuries of mostly government-financed scientific endeavour. Furthermore, many of the users would be information providers as well. Taking over of marginal costs was still seen as a possibility, as was charging commercial users of the service. However, the general feeling was that the administrative and IPR-related complications inherent to that approach by far outweighed the income generated. For example, several of the thematic networks which are accessible through BioCISE provided their data with the explicit condition that they should be available free of charge.
Again, flexibility of the system is decisive: it has to be able to survive changes in its administrative set-up and location as well as changes in on the information providers side. The system software should require minimum maintenance; once installed, the maintenance and provision of base data will lie in the responsibility of national and thematic networks driven by user and provider communities. The BioCISE project has already established links to 5 national and thematic networks, and the set-up of other National Nodes has been organised in view of pending project proposals. Established contacts to European agencies and the CHM, and liaison with the Consortium of Large-scale European Taxonomic Facilities (CETAF) further broaden the base for attempts to achieve long-term sustainability.
Collection information serves as a basis for biodiversity research, which is part of the obligations incurred by government in the context of international conventions. Interconnecting such databases of a variety of nations and scientific research topics is a justified cause to involve international research funding agencies. A biological collection information service integrating the full spectrum of resources would play an important role in the Global Biodiversity Information Facility (GBIF 2000) envisioned by the OECD Megascience Forum Working Group on Biological Informatics (Edwards 1999).
The creation of a Biological Collection Information Service in Europe is believed to be a feasible goal if an approach relying on scalable metadata provision through a network of national nodes is used. The major initial contributions an international implementation project would have to make are the following:
A project period of 3 years with adequate resources is deemed necessary to achieve a functioning service. Questions of sustainability of a collection information service, the adequate consideration of intellectual property rights, and approaches towards data quality standards will have to undergo continued discussion.
© BioCISE Secretariat. Email: biocise@, FAX: +49 (30) 841729-55
Address: Botanischer Garten und Botanisches Museum Berlin-Dahlem (BGBM), Freie
Universität Berlin, Königin-Luise-Str. 6-8, D-14195 Berlin, Germany